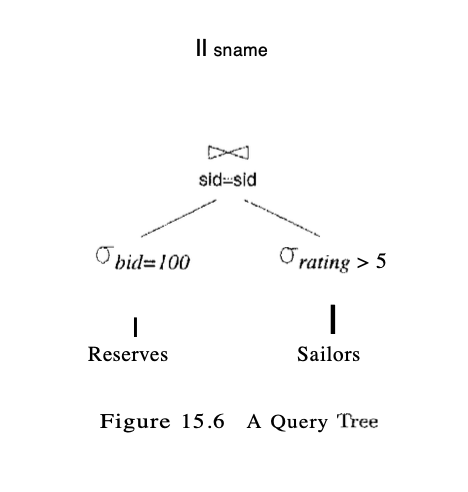
Query Optimization
Execution Tree:
- Leaf Nodes: base relations
- Inner Nodes: operators
- Tuples from the base relations flow into the parent operator nodes
- Output of an opterator nodes flows into the parent node
- Output of the root flow as result to the client
SELECT GM.gid, count(*), AVG(U.age)
FROM Users U, GroupMembers GM
WHERE U.uid = GM.uid AND U.experience = 10
GROUP BY GM.gid
HAVING AVG(U.age) <25
A corresponding example execution tree:
Pipelining
-
Definition 1: As soon as an output tuple of an operator is found, it is forwarded to the next operator
-
Definition 2: As soon as one ouput frame in the memory buffer is full, it is processed by the next operator
-
Enables parallel execution of operators
-
No write to disk costs for intermediate relations if it can be avoided
SELECT *
FROM Users U, GroupMembers GM
WHERE U.uid = GM.uid
AND experience = 10
Assumptions:
- 50 buffer frames available
- 40,000 tuples on 500 UserPages
- 1,000 GroupMember pages
- 1% of users have experience = 10 i.e. 400 users
- Each User tuple has on average 2.5 GM tuples
- In the execution tree, selection is done first, and the resulting tuples are pipelined directory to the join
Which join is best?
Block Nested LoopCost:
Index Nested LoopCost:
Sort Merge JoinCost:
Optimization Techniques
Two types of optimization techniques:
-
Cost-Based Optimization:
- Calculate and compare the I/O cost of possible implementations of operators.
-
Algebraic Optimization:
- Prioritize operations that eliminate a lot of tuples
- push down selections and projections
- Order joins to have intermediate results with minimum number of tuples and tuple size
Algebraic Optimization
Push down projections, selections and joins to their respective relations
Note: need to be careful that projecting does not remove attributes that might be needed later on in.
ExampleSELECT u.name, u.experience
FROM Users U, GroupMembers g
WHERE u.uid = g.uid
AND g.gid = "G1"
AND u.age > 20
This query can be expressed in algebraic form as:
where the order of operators is first join, then selection, then projection.
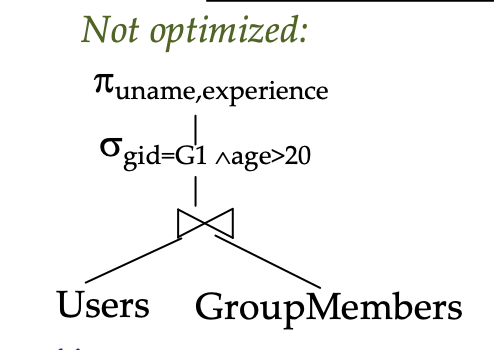
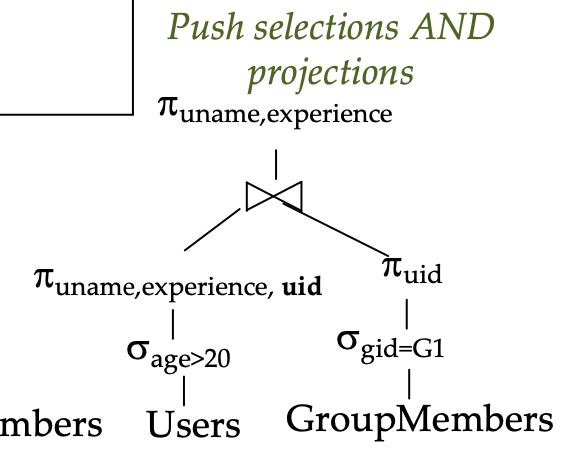
Pushing projections down the execution tree wont reduce the number of tuples but it will reduce the memory size of intermediate results as attributes are trimmed from each tuple.
General rules of thumb
- If the application has certain kinds of queries that will be run frequently, create appropriate indexes to speed up these queries
- If the application has many updates and inserts, be conservative with creating indexes for the relevent relations since each INSERT/UPDATE will also change the index tree.
SQL EXPLAINexplains how a query is executed internally.